Please refer to my CV for updated highlights of my research activities.
In my research, I develop and analyze foundational machine learning models and algorithms, including problem domains such as comparison-based recommender systems and active learning. With a background in statistical signal processing, I view many of the problems I work on through the lens of efficient information acquisition: given some source of data, how can a minimal set of measurements (or labeled data points) be selected and processed in a computationally efficient manner to learn a generalizable model. While many of the techniques I work on can be applied to general sources of data, I’m particularly interested in human-in-the-loop settings, where the information source is a human labeler training a machine learning system on a particular task. To reduce burden on the human labeler, the number of requested labels should be minimized, as well as the processing time (and therefore computational cost) between each labeled example.
I typically approach my research problems using concepts from information theory, adaptive sensing, low-dimensional and generative modeling, and Bayesian statistics, among other tools. I’ve worked on problem domains including active classification, metric learning, preference learning, ordinal embeddings, adaptive search, image segmentation, brain-computer interfacing, explainable AI, and deep generative modeling.
See below for additional details on each of my research thrusts, or my publications page or Google Scholar page for a complete list of publications.
Localization and preference learning from paired comparisons
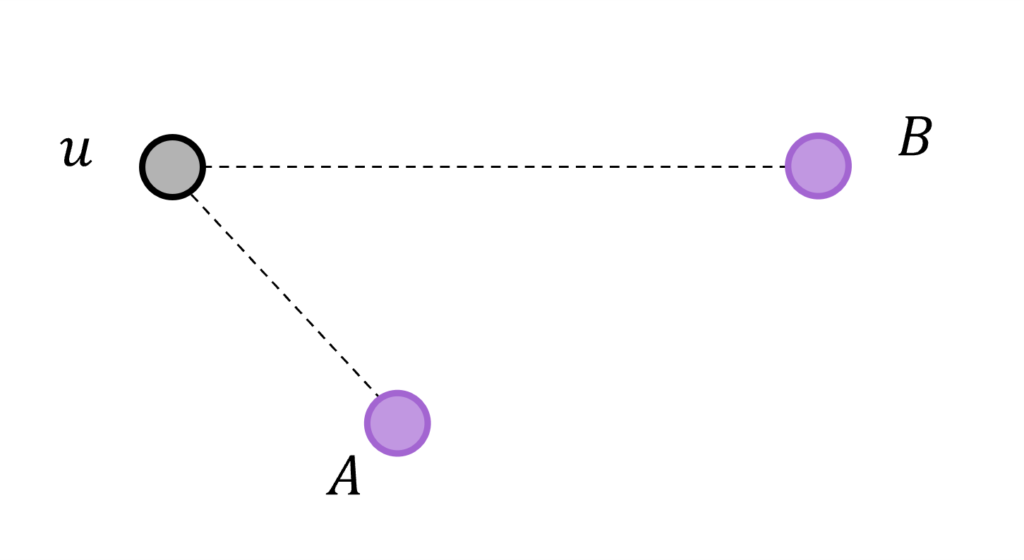
Consider the problem of locating a point u in some d-dimensional vector space by measuring distances to a set of known landmark points in the same space – this is a classic problem studied in signal processing, and is a generalization of problems such as finding one’s GPS location from distance measurements to satellites. Now, however, suppose that only one-bit paired comparisons between landmark distances are measured in the form of “is u closer to landmark A or landmark B?” In the series of projects described below, I study questions surrounding how and when u can be estimated from measurements of this form.
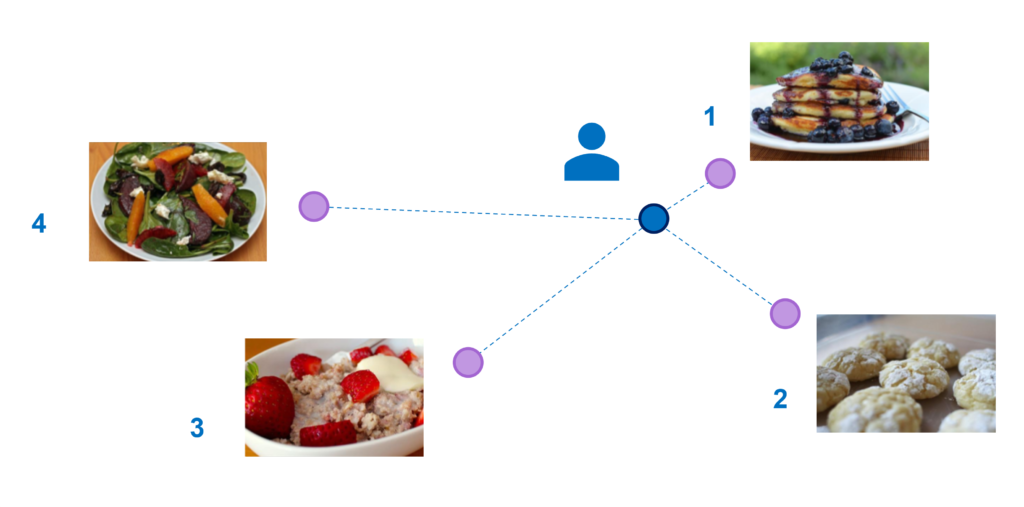
One popular application of this paired comparison model is in preference learning for a recommender system. In this model of preference, items such as different food dishes are embedded in a multidimensional feature space, and the task for a given user is to assign them a vector u in the same space, under the assumption that the user prefers items closer to their point u over items further away. Once learned, the point u can be used in a recommender system by suggesting items close to u. To learn u, paired comparison queries are made to the user in the form “do you prefer item A or item B?”, which mathematically translates to distance comparisons in the localization model described above. Throughout my work, I use preference learning from paired comparisons as a lens to study the more general localization problem from one-bit distance measurements.
Active embedding search via noisy paired comparisons (ICML 2019)
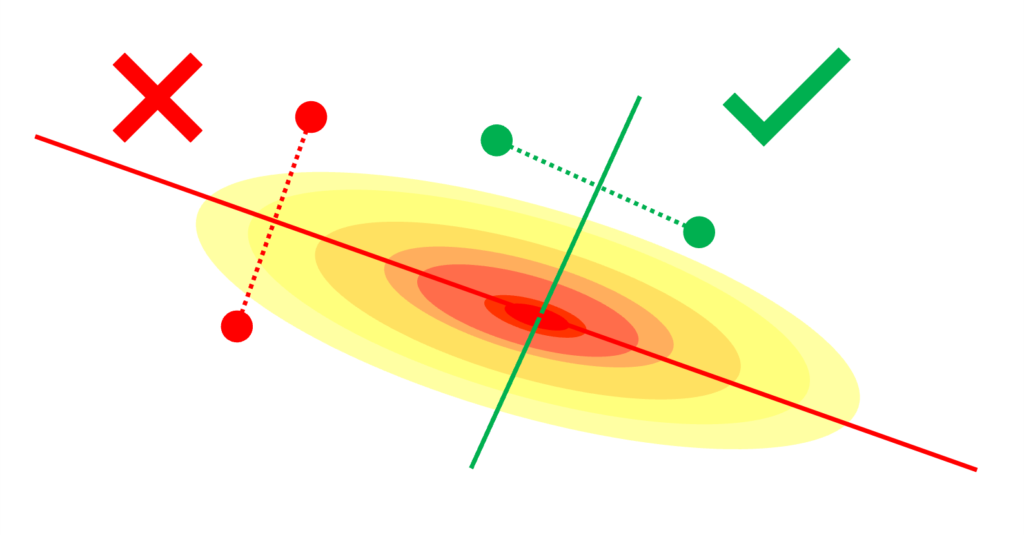
In many applications, paired comparison measurements may be expensive to obtain, such as in preference learning from humans where answering a large number of such queries may be mentally taxing. In such problems, measurements can be selected intelligently (or actively) to only query the most informative pairs, rather than selecting queries uniformly at random. In this work, we devise and analyze active query selection strategies for localization from paired comparisons and demonstrate sample complexity improvements over random sampling. [paper] [code]
Joint estimation of trajectory and dynamics from paired comparisons (CAMSAP 2019)
In certain localization problems such as a vehicle moving through an environment or a user whose preferences change dynamically, it may be the case that the target u changes its position over time according to some unknown dynamical system. In this work, we use active selection techniques to simultaneously estimate the moving target u and identify the underlying dynamics that govern its evolution.
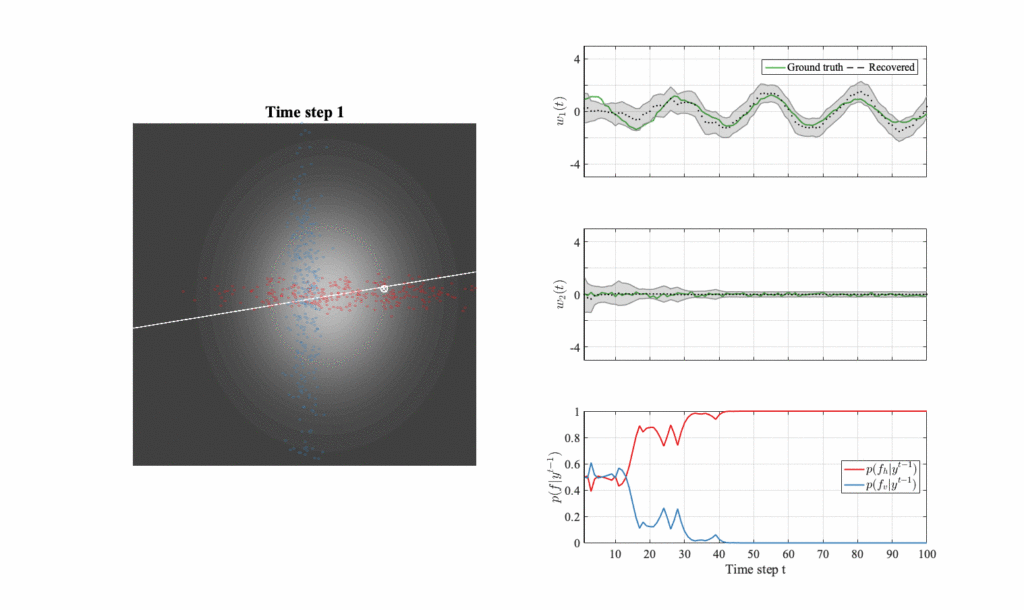
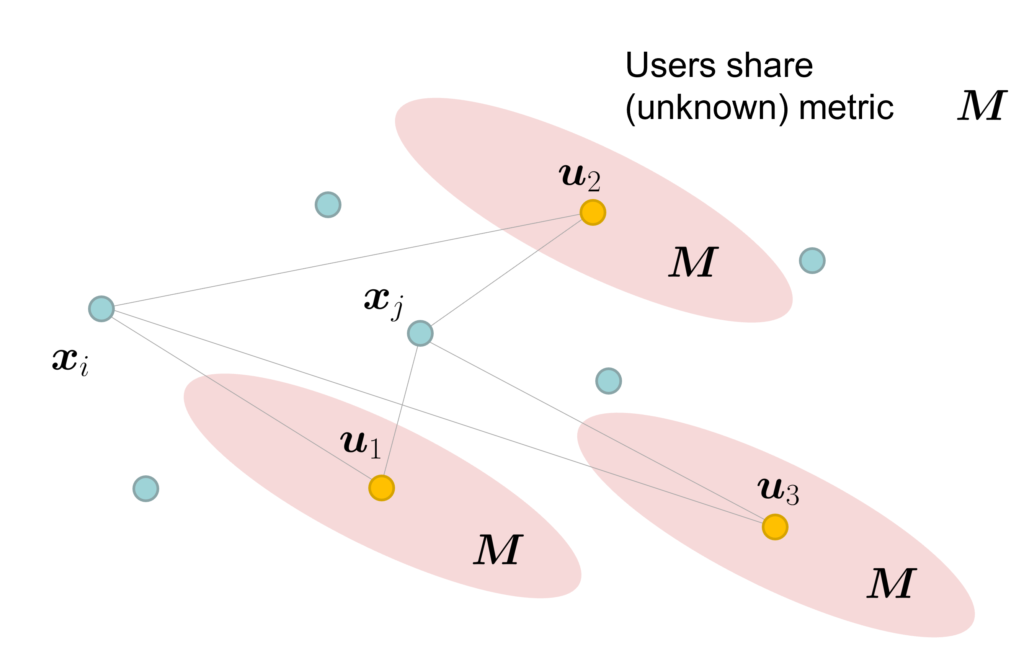
One for all: simultaneous metric and preference learning over multiple users (NeurIPS 2022)
In certain applications of preference learning from paired comparisons, it may be the case that the distance metric governing comparison responses is non-Euclidean: in other words, certain features in the item embedding space are weighed more than others when users make preference judgements. In this work, we study an extension of the pairwise preference learning problem where we not only learn the user’s ideal point u, but also the underlying (possibly non-Euclidean) metric that governs their judgements. We show that when learning simultaneously over multiple users that all share the same metric, the sample cost of learning the metric is distributed over the crowd, requiring only a modest number of comparisons per user. [preprint] [code]
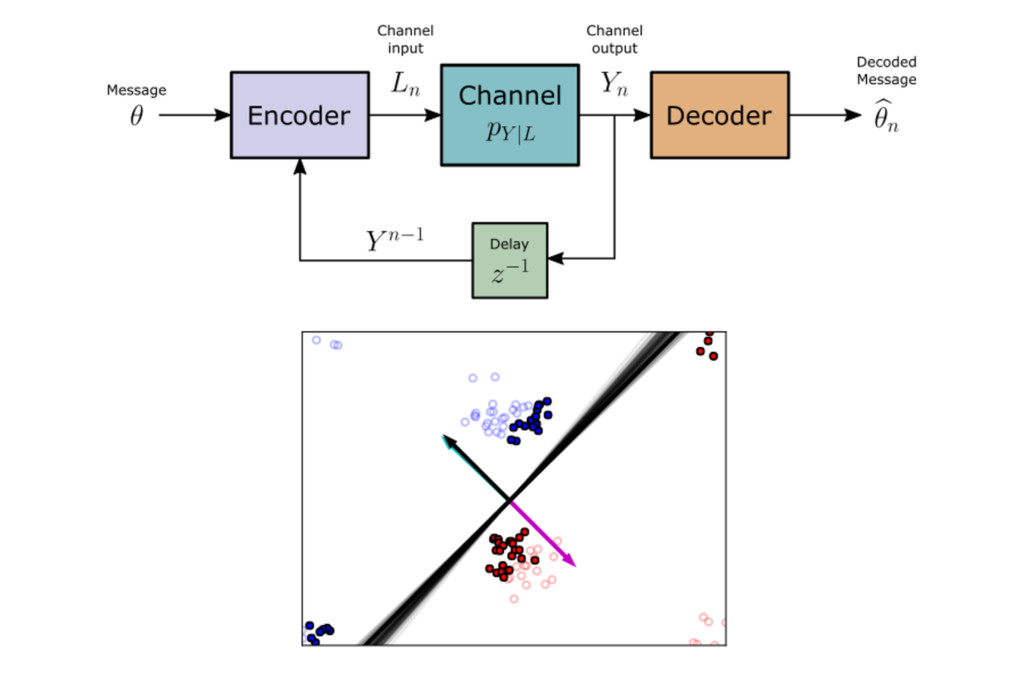
Feedback coding for active learning (AISTATS 2021)
The problem of active learning is fundamentally a study of information acquisition with feedback. In telecommunications, such problems have been studied for decades in the context of communicating over a noisy channel with feedback. While information theory has been heavily leveraged in the study of active learning, the direct treatment of active example selection as a problem of coding with feedback is a fascinating intersection that has not been deeply explored. In this work, we directly reframe active learning as a feedback communications problem, and adapt a recently developed feedback coding strategy to the problem of example selection in logistic regression. [paper] [code]
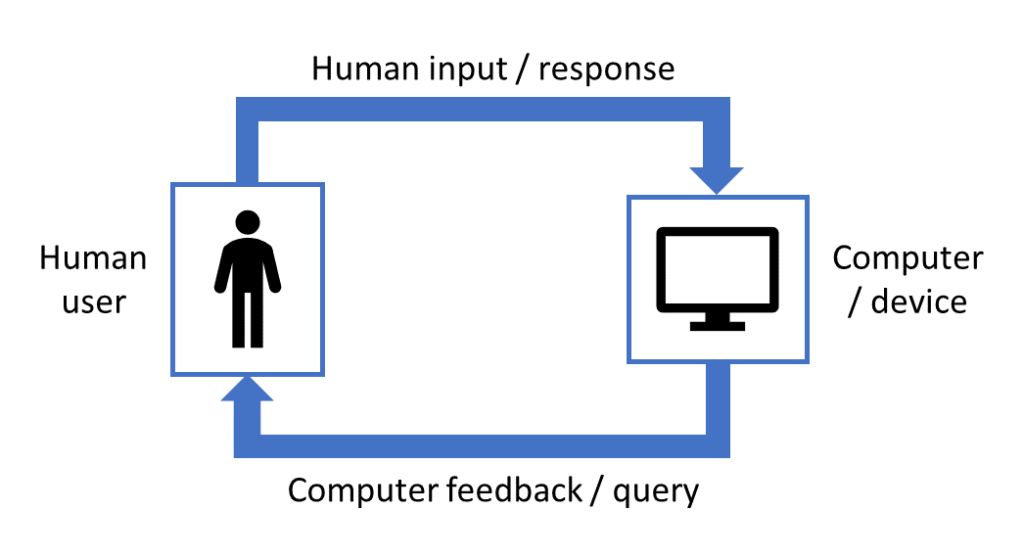
Information acquisition with feedback for human-in-the-loop systems
There are countless human-in-the-loop systems where a human user has some mental model or intention that they wish to convey to a computer, and the computer ascertains this information through a sequence of queries or interactions with the human. Such tasks extend beyond traditional machine learning where humans simply provide data labels, and include problem domains such as learning a psychometric model for how humans perceive objects, or device control tasks where a human wishes to specify a particular system behavior. Just like in active machine learning, in such settings it is typically the case that interacting with a computer places a high burden on the human user (for example, is time and energy consuming or expensive), and therefore we wish to minimize the number of interactions between the human and computer. In the projects below, we utilize tools from information theory to sequentially determine which queries or interactions are the most informative to the computer, to minimize burden on the human user.
Active ordinal querying for tuplewise similarity learning (AAAI 2020)
A classic problem in psychometrics is learning a mathematical model for how humans perceive similarity between objects. Such models can be learned by asking humans to order multiple objects based on perceived similarity. Our contribution to this field is a method to select maximally informative queries of this type to minimize the total number of queries needed to learn an object similarity model. Specifically, we ask users ranking queries of the type “rank items B1, B2, … Bk according to their similarity to object A.” We show how selecting informative queries can reduce the number of interactions needed when compared to randomly selected queries. Furthermore, we show that asking about more objects at once is more efficient than asking about fewer objects at once. [paper]

Interactive object segmentation with noisy binary inputs (GlobalSIP 2018)
For many people, it is easy to take for granted the capabilities they have when interacting with computers, such as using a mouse and keyboard to specify actions. However, for other people these interaction types are difficult or impossible, such as paralyzed users who only have limited means to interact with a computer (for example through detected eye or tongue movements). For such users, common computer tasks such as specifying an object in an image are impractical or impossible. In this work, we devise a method to specify an object segment in an image using only one-bit interactions, where these interactions are selected to be as informative as possible to reduce user burden. We accomplish this by constructing a learnable dictionary of image segments and utilizing a method resembling binary search that allows a user to efficiently navigate this dictionary using only single bit commands.

A low-complexity brain-computer interface for high-complexity robot swarm control (IEEE TNSRE, 2023)
Just as some users may have limitations in interacting with a computer for tasks such as image segmentation, people with debilitating diseases such as ALS face tremendous challenges in interacting with the world around them. One approach to aid such users is to directly measure electrical activity from their brains and translate these signals into commands that operate devices such as text entry keyboards or motorized wheelchairs. We construct such a “brain-computer interface” or “BCI” using similar techniques as described above for image segmentation, where instead of specifying image segments the BCI user controls a physical device. Specifically, we advance an information-theoretic method that allows a BCI user to encode their desired system behavior using only one-bit mental commands based on an intuitive set of instructions. As a proof of concept for controlling a high-complexity device, we demonstrate this BCI technique for the task of controlling a swarm of mobile robots using only mental commands. [preprint]

Deep generative modeling for interpretable machine learning
Deep neural networks have achieved remarkable performance in countless classification and data generation tasks on large, high-dimensional datasets. Yet, the data representations learned by such models are usually opaque and difficult to interpret by machine learning practitioners. Below I describe two projects I collaborated on that make strides in increasing the interpretability of deep learning models.
Generative causal explanations of black-box classifiers (NeurIPS 2020)
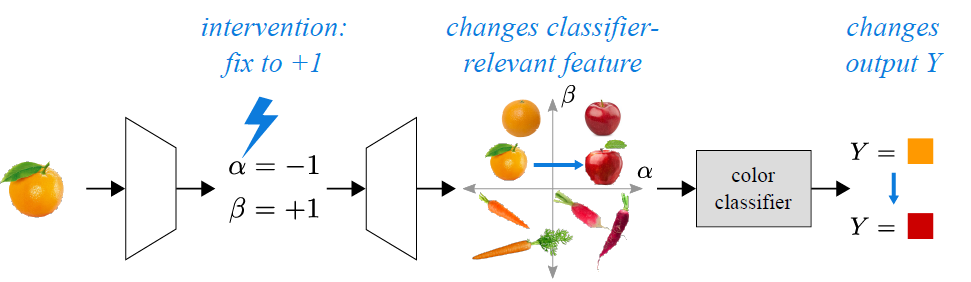
In many cases, deep classification networks are arguably “black-boxes,” where it is unclear how they make their classification decisions based on input data. In this work, we use tools from causal inference and information theory to develop a black-box explanation method that capitalizes on the following perspective: the data “aspects” that matter most for classification by a trained model, if perturbed, will have a significant impact on the model’s classification output. We use this insight to train a generative model that specifically learns the feature space aspects responsible for the most significant changes in a black-box’s classification output. Once trained, our explanation method allows a practitioner to observe which aspects of a particular data example matter most when classified by a black-box model. [paper]
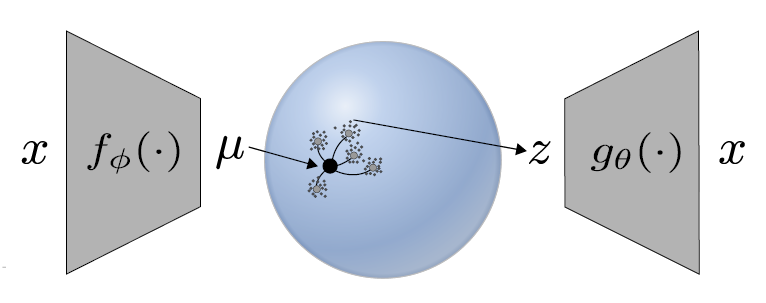
Variational autoencoder with learned latent structure (AISTATS 2021)
In the widely popular variational autoencoder, a generative model is trained to learn a compact, latent representation for the feature variations in a particular dataset. However, the learned latent structure is typically fixed ahead of time, without adapting to the underlying manifold structure in the data distribution. In this work, we utilize tools from manifold learning to construct a variational autoencoder variant that adapts to the underlying low-dimensional structure in the training data. Importantly, our trained model outputs a set of interpretable manifold operators that describe the learned low-dimensional structure for a particular dataset. [paper]